[This post describes research from the paper Crosslingual Topic Modeling with WikiPDA, published at The Web Conference 2021. Code and data are available on GitHub. A technical talk is available on YouTube.]
If you have ever worked with the content of Wikipedia for your research, you have certainly come across the problem of automatically recognizing what topics an article is about. Indeed, having a way of automatically recognizing the topics covered by one page enables researchers to address a large set of questions. Examples span from measuring the semantic distance between documents, to investigating how Wikipedia covers different subjects, to monitoring evolving trends.
At this point, if you are familiar with topic modeling, you will probably think to yourself that Latent Dirichlet allocation (LDA) is a great solution for this problem. LDA uses a bag-of-words model to infer, for each document, a distribution over multiple topics that are discovered automatically from the corpus that is given as input. In other words, starting from the words in the article, LDA returns a probability distribution over K topics, where K is a value specified as an input parameter.
But here’s the catch: an important aspect of Wikipedia is that it exists in nearly 300 languages! How can we compare the topics of articles that are written in different languages? For example, how can we answer questions such as these: Is Wikipedia in German covering the same topics as in English? What are the most similar Wikipedia editions topic-wise? Are there topical biases for different languages? Suppose we train an LDA model using the words contained in Wikipedia articles. In that case, since LDA infers the set of topics automatically in an unsupervised way, we would obtain topics that are specific to the corpus (i.e., language) used and that are therefore not comparable across languages.
Wikipedia-based Polyglot Dirichlet Allocation (WikiPDA) is our solution to this problem. WikiPDA solves the problem by leveraging the fact that Wikipedia articles are aligned across languages via the Wikidata knowledge base. This allows us to achieve a language-independent topic model by first describing the documents with tokens that do not depend on the original language and only then, with this alternative representation, applying a well-established topic modeling method like LDA.
How does it work?
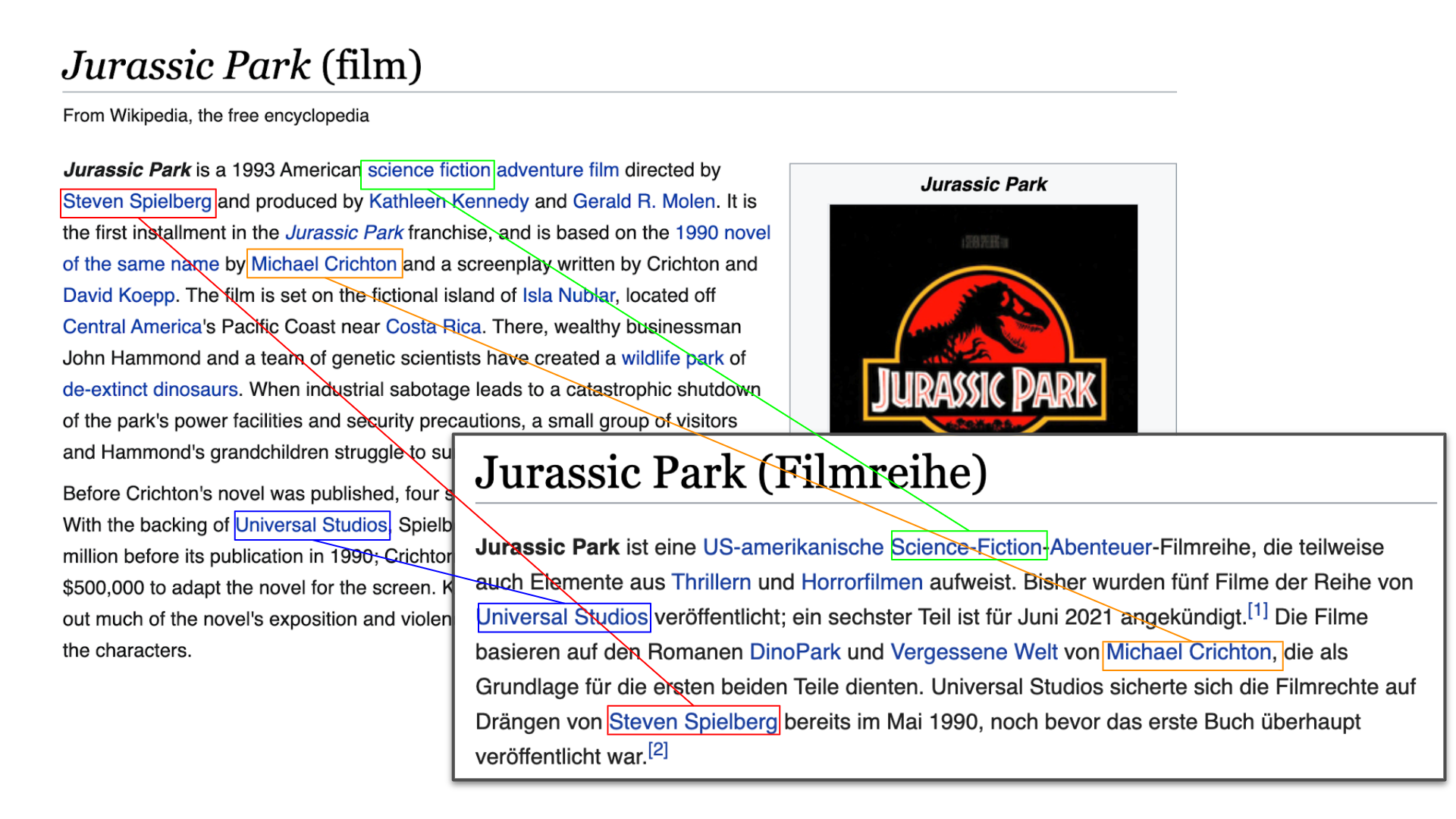
If we think about what elements Wikipedia articles about the same entity written in different languages (see Jurassic Park example above) have in common, we will notice some shared elements. Above all, we realize that the articles share many links to the same entities. For example, two articles about Jurassic Park, regardless of their language, will contain links to Steven Spielberg (the director), the movie genre, the production company, the release format, etc. The great news is that, since Wikidata tells us which articles written in different languages correspond to the same entity, we can replace these links with Wikidata entity identifiers. This way, we can effectively represent each original article without using any language-specific information, which in turn allows moving from language-dependent bags-of-words to language-independent bags-of-links, or bags-of-entities. This is the main intuition behind WikiPDA that enables us to use an effective method like LDA on Wikipedia without worrying about the article’s original language!
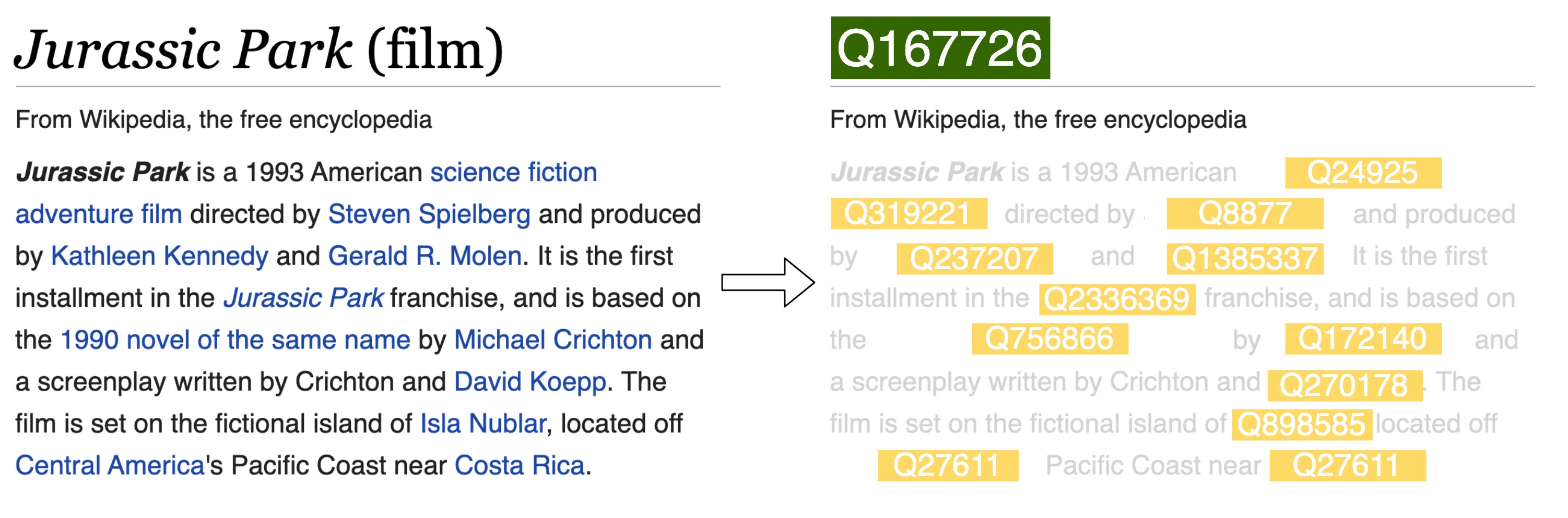
But before proceeding with the LDA training, our last step is to make this alternative representation with a number of tokens comparable to the word-based model. Each bag-of-links is limited to the links present on the respective page, and it can be a very limited representation. For example, short documents or languages that have smaller volunteer communities can have very few links. This can pose a challenge in learning high-quality topics with standard LDA, where typically we can rely on rich representation with documents longer than one single sentence. We approach this problem by creating virtual links for all the words that potentially have an associated Wikipedia page. We call this step link densification, and if you want to learn more about it, please refer to the technical paper.
We trained WikiPDA in order to represent more than 20M articles in 28 languages from a diverse set of language families, scripts, and cultures: Albanian, Arabic, Catalan, Chinese, Czech, Dutch, English, Finnish, French, German, Greek, Hebrew, Indonesian, Italian, Japanese, Korean, Persian, Polish, Portuguese, Romanian, Russian, Serbian, Spanish, Swedish, Turkish, Ukrainian, Vietnamese, Waray. We make the pre-trained models for different numbers of topics K (compatible with Gensim and Pyspark) publicly available. One really nice aspect of WikiPDA is its ability to perform “zero-shot language transfer”, where a model is reused for new languages without any fine-tuning on the new languages. For instance, WikiPDA allows you to infer topics for a Wikipedia article written in Estonian (which is not among the 28 languages used for training the published model) without any extra effort, compared to the 28 languages that we used for training.
Applications
Now that we have language-independent topic models for Wikipedia, what can we do?
Visualize topical biases. The first aspect that we can finally study is the language-based content bias. For example, does Wikipedia in Waray have articles about the same topics as the English edition? To visually inspect if there is any difference at all, we reduce the topics distribution to two dimensions with t-SNE and look at the density in the resulting two-dimensional space. By applying this reduction to different languages, we observe completely different topic concentrations:

This visualization does not give an easy way to interpret what are the major differences across languages, but still, it is a clear hint that topical biases in the different languages can be observed and measured.
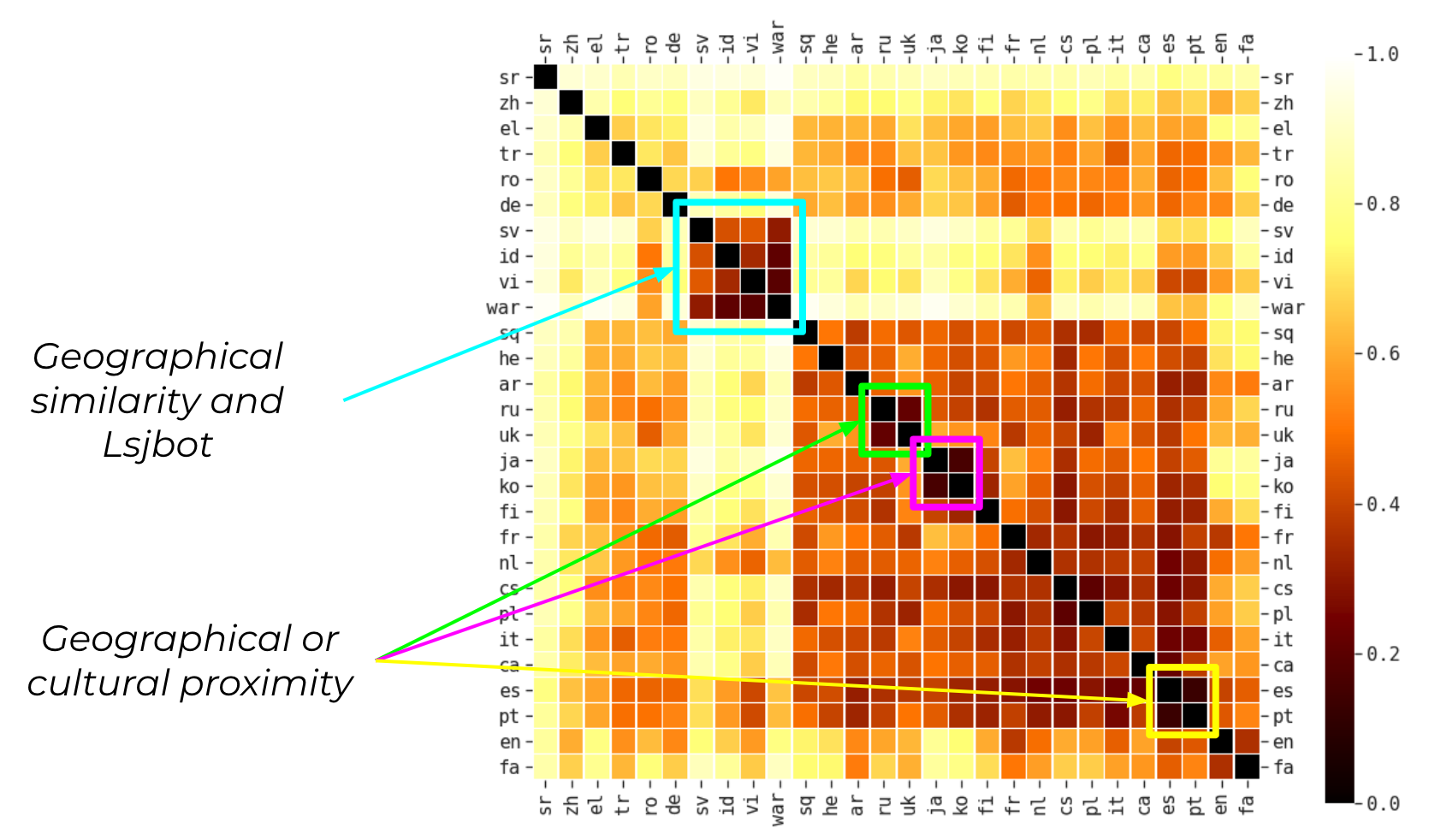
Distance between languages. Another interesting application is to actually measure the topical distance of the different language editions. This analysis is useful to understand what language editions are growing together and influence each other. One simple approach is to represent each language by averaging all its articles’ topic distributions and computing the cosine similarity. By plotting the distance between every pair of languages as a heatmap, we notice similarities between the articles of languages that share geographical or cultural proximity. Some examples are Russian and Ukrainian, Japanese and Korean, and Spanish and Portuguese. Also, we notice another cluster of culturally similar languages, like Waray and Indonesian, and Vietnamese. What is interesting is to see Swedish in this group. We investigated the reason for this unexpected similarity, and we discover that Waray and Swedish both use the same bot (Lsjbot) that automatically creates articles in each of the two languages.
How can you use WikiPDA?
At github.com/epfl-dlab/WikiPDA, we released all the pre-trained models, and to make things even easier, we also developed an easy-to-use Python library that allows you to get the topic distribution of any Wikipedia article with just a few lines of Python code.
A sample of the library is also deployed as a Web API at wikipda.dlab.tools and can be queried with a handy REST interface. Please let us know your impressions and experience!
A few notes about the evaluation
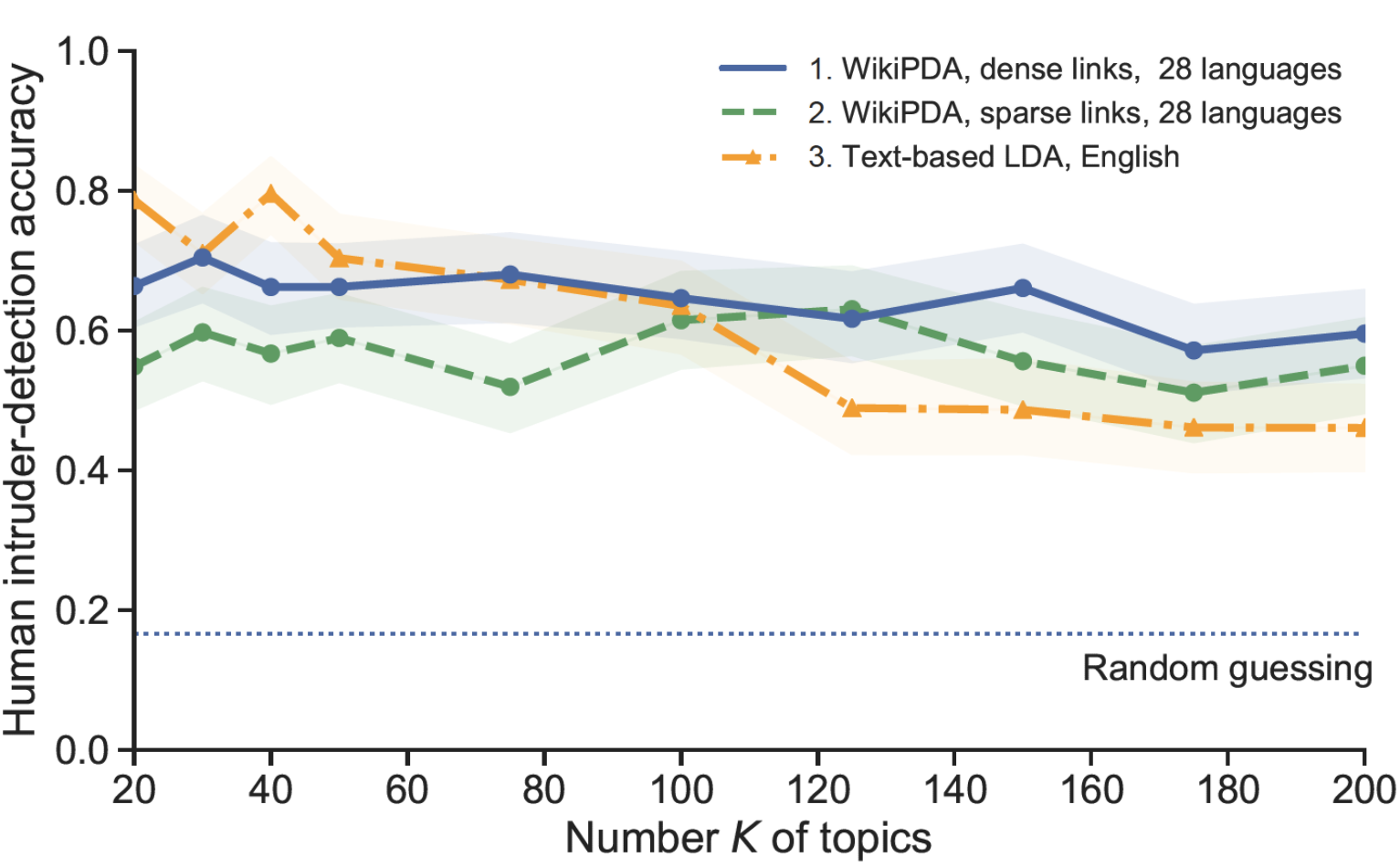
Evaluating a topic model is not an easy task. In the case of WikiPDA, we want to make sure that the topics generated are consistent and that changing the paradigm from bag-of-words to bag-of-links does not hurt the quality significantly. We could use automatic methods such as perplexity scores, but they have two big issues: the resulting scores are not easily comparable when the corpus is not the same (words vs. links corpus), and they do not always correlate with human judgment [2]. Since we aim to have an interpretable model, we evaluated the quality directly by asking humans, in a crowdsourced evaluation based on the word-intrusion framework proposed by Chang et al. [2]. (For details, see the technical paper.) We found that WikiPDA performs very well. When comparing WikiPDA to a standard text-based LDA model trained specifically for English, we found that WikiPDA performs better even though it uses only links rather than full article texts (see plot below) In appreciating this result, it’s important to note that the text-based LDA model is not language-independent and thus not truly a competitor with crosslinguality in mind. Rather, it should a priori be considered a strong ceiling: text-based LDA is the de-facto standard for analyzing the content of Wikipedia articles in monolingual settings. Thus, by surpassing the topical coherence of text-based models, WikiPDA offers crosslinguality “for free”.
References
[1] Aaron Halfaker and R. Stuart Geiger. 2020. ORES: Lowering Barriers with Participatory Machine Learning in Wikipedia. Proc. ACM Hum.-Comput. Interact. 4, CSCW.
[2] Jonathan Chang, Jordan Boyd-Graber, Sean Gerrish, Chong Wang, and David M. Blei. 2009. Reading tea leaves: how humans interpret topic models. In Proc. International Conference on Neural Information Processing Systems (NIPS’09).