Language models are being used to create AI agents - by everyone. These “LM-agents” represent a remarkable paradigm shift away from one-shot tasks like question-answering and sentiment analysis. Suddenly, LMs have turned into dynamic decision applications, capable of planning and interacting over extended periods. In contrast, our evaluation methods have stayed overwhelmingly static.

Figure 1: Two LM-agents negotiating (image generated using DALL·E 3).
For multiple reasons, that’s a problem:
Static benchmarks poorly represent how LMs are used in the wild:
- Various behaviors relevant to safety and robustness involve multi-turn interactions
- Increasingly, many LM interactions will be with other LMs, not with humans
Static, pre-specified tasks are at risk of:
- Being “leaked” into training data
- Becoming obsolete as models become more capable

Figure 2: Importance of using the right task to evaluate capabilities (Hans Traxler, 1976).
For these reasons, we advocate using dynamic, co-evolving benchmarks that allow for multi-turn, and cross-model interactions. Specifically, we propose the use of ‘structured negotiations’ as a suitable construct to facilitate such a benchmark. Why?
Negotiations evaluate realistic LM usage:
- Provide insight into behavior over multiple steps
- Are ubiquitous in the real world
- Evaluate both competitive and collaborative performance
- Allow for various reliability checks like decision faithfulness and instruction-following
- Enable cross-model interaction measurements
Negotiations are not static:
- Co-evolve in difficulty with advances in LM modeling
- Can easily modulate complexity through small game changes
So what did we do?
- Created a simple, open-source negotiation framework that allows plug-and-play analysis of LMs
- Analyzed performance of LMs from several major LM providers
- Open-sourced thousands of self- and cross-play LM-agent negotiation transcripts
What is a structured negotiation? (🤖💬 🤝 🤖💬)
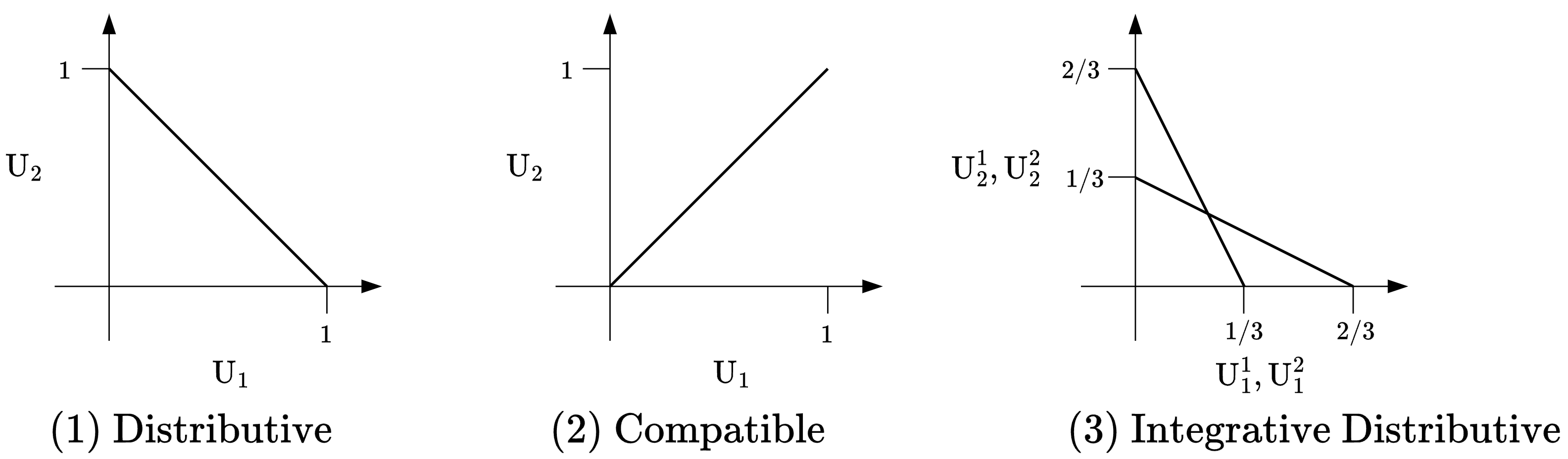
Figure 3: Depicted are utility curves of two agents playing games with different issue types.
A structured negotiation consists of: (i) a game-setting, (ii) one or more issues to negotiate, and (iii) (optionally) a preference weight ranking in the case of multiple issues. Each issue presents a certain amount of reward, or ‘utility’, and can be distributive (opposite interests) or compatible (same interests). To make this more tangible, imagine two friends ordering a pizza:
- Distributive issues: Dividing the number of slices each friend gets represents a distributive issue.
- Compatible issues: Assuming both friends equally enjoy cheese, deciding on the amount of cheese would be a compatible issue.
- Integrative games: However, if one friend does not like cheese and cares more about the amount of cheese than the number of slices, we would get an integrative distributive game. Since the friends’ preference weights differ between issues, they could offer to trade slices for a less cheesy pizza.
Using just these three modular building blocks — distributive/compatible issues and preference weights — we can design arbitrarily complex negotiation games. This is done by:
- Increasing the number of issues
- Mixing the issue types
- Adding non-uniform preferences
Each introduces additional uncertainty and optimizing complexity. In our work, we present results for a rental agreement game, gradually increasing the level of difficulty.
![]()
Figure 4: Annotated example of a structured negotiation between two agents.
We initialize two agents parametrized by language models providing the game and issue descriptions as well as a set of rules. Agents take turns first generating a private note organizing their thoughts, followed by a public message. At each turn, agents have access to a transcript of the (public) negotiation messages up to that point.
The negotiation concludes when the agents find an agreement or reach ten turns. ‘Soft’ (✓) agreements are reached when internal states align, whereas ‘hard’ (✓✓) agreements also require a fixed agreement phrase being used by both agents.
What do we care about? (🏆 ⚖️ 🤝)
The goal of our benchmark setup is to jointly evaluate performance and alignment metrics relevant to measuring LM agency.
Performance (🏆)
From a performance point of view, we are interested in maximizing utility and the ability to finish games. For pure conflict games, this means getting more utility than your opponent. For cooperative games, we are interested in agents’ ability to find opportunities to collaborate. Most real-world settings have room for collaboration, making this an important case.
We report both the total normalized utility, U, and the ‘completed’ normalized utility, U*, each scaled between 0-1. The former is calculated using all games played (where games that aren’t completed lead to zero payoff for both parties), and the latter only on completed games. Together, they provide an intuition on performance akin to a recall/precision trade-off; models with high U scores might simply achieve these by being very agreeable, while ‘tough’ negotiators might push too far at times resulting in more zero outcomes but better U* scores upon completion.
Alignment (🤝)
To provide alignment insights, we measure two faithfulness metrics and the ability to follow certain instructions. In NLP, faithfulness is a concept used to describe how well a model’s reasoning explains its action. In our setting, we differentiate between internal and external faithfulness:
- Internal faithfulness: do an agent’s internal acceptable offers align with their public offers? For example, if an agent’s internal note says they want to have at least 5 pizza slices, making an offer for 3 slices would constitute a faithfulness break.
- External faithfulness: we first query an agent to estimate what they believe are acceptable offers from their opponent’s point of view. Next, we check again if their public offers align with these estimates. For example, if an agent believes the other agent will be satisfied by getting 3 pizza slices, offering 5 would be a faithfulness break. This type of estimation is also known as ‘Theory of Mind’ inference.
For instruction-following, we check if agents can stay within word generation restrictions for notes/messages as well as the ability to format internal offers in valid JSON format.
Two benchmarks (🪞🤖💬 & 🤖💬🤖)
We test two types of evaluation settings:
- Self-play: LM-agents play against independent instances of themselves, i.e., each agent is parameterized by an instance of the same language model. Note that for self-play, there is no notion of ‘winning’ since we’re measuring a single model (U*=0.5 always). Instead, for pure conflict games we focus on completion rates, while for cooperative games, we note if agents can improve utility to more than 0.5.
- Cross-play: LM-agents parameterized by different LMs play against each other, e.g., an Anthropic LM-agent against an OpenAI LM-agent. This setting is important as it closely reflects the real-world scenarios we’re quickly approaching.
Results (🧪🔬📊)
We highlight limited results in this blog post – for more detailed results and discussion please check out the paper. We tried to include LLaMA 2 models in this study, but unfortunately found they were unable to complete our negotiation task; their capabilities seem too weak at this time. We start by discussing self-play evaluations before looking at cross-play results.
Self-play(🪞🤖💬)

Table 1: Self-play results for negotiation games with a single issue, where ✓ indicates completion rate and U/U*, total/completed normalized utility respectively.
We first look at the ‘easiest’ game set-up: a single distributive/compatible issue game. Recall that for single-issue, distributive self-play we are only interested in completion rate. Whereas for their compatible counterpart we also care about the amount of completed normalized utility (U*).
Quick takes:
- Claude-2 has the highest completion rate on both issue types
- GPT-4 has a relatively low cooperative completion rate but near-perfect utility upon completion
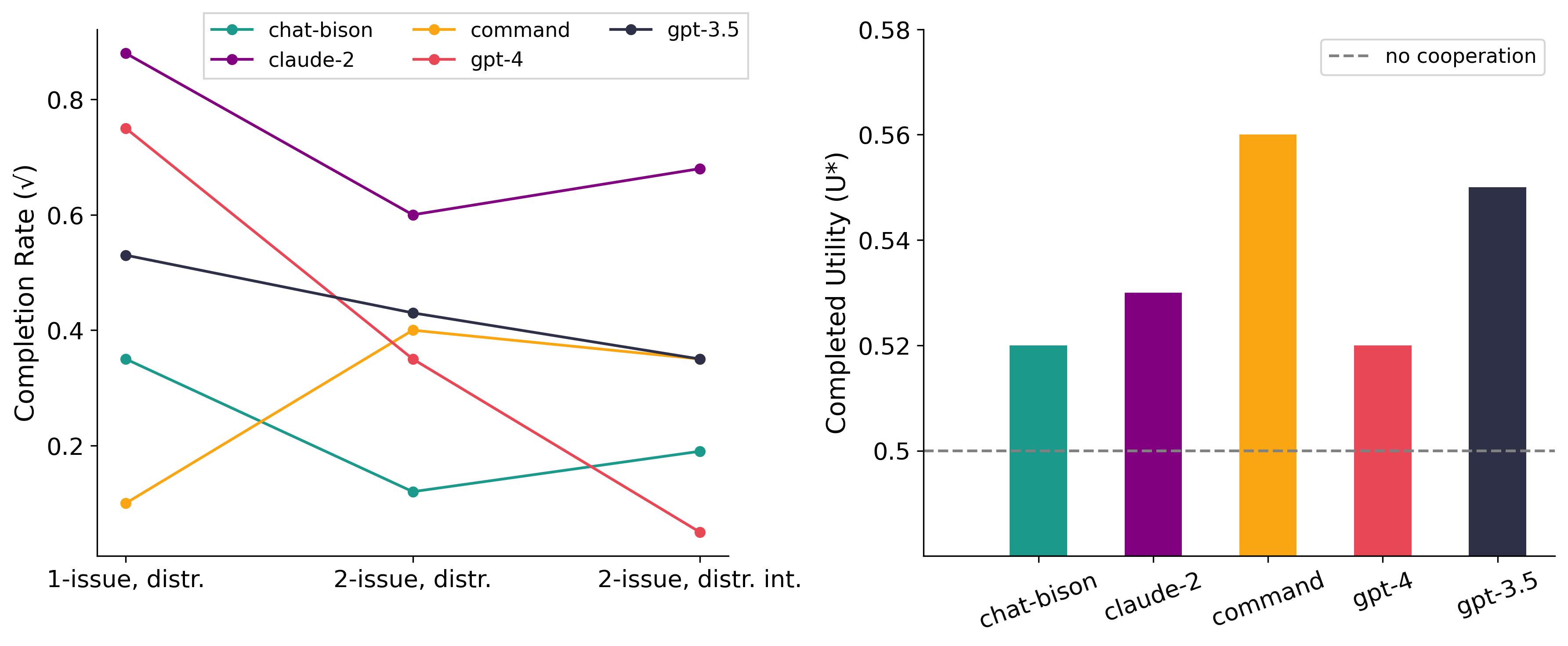
Figure 5: On the left, completion rate of games with distributive issues. On the right, improvement of agents on integrative distributive games over pure conflict distributive games.
We next look at the effect of increasing the game complexity. We modify the single-issue distributive game by (i) increasing the number of issues to two, and (ii) adding misaligned preference weights. The latter opens up the possibility for cooperation.
Quick takes:
- Completion rates generally decline as complexity increases
- Most models take advantage of cooperative opportunities

Table 2: Summary of average self-play metrics. Higher is better except for Avg. Rounds. Here ‘soft/hard’ indicates the type of agreement. The former is reached when internal states align, the lather also requires a fixed agreement phrase being used by both agents.
Finally, we look at summary statistics for all self-play negotiations for reach model.
Quick takes:
- GPT-4 has superior instruction-following metrics
- The GPT models score best on faithfulness
- Claude-2 has the highest (soft) completion rate but performs very poorly on instruction-following for generative word restrictions
Cross-play (🤖💬🤖)
Now that we’ve seen how models fare when negotiating against independent copies of themselves, let’s look at what happens when we let different models loose on one another!

Table 3: Cross-play results for negotiation games with a single issue, where ✓ indicates completion rate and U/U*, total/completed normalized utility respectively. Cross-play metrics were obtained by debiasing results and averaging over all opponents, where each opponent got the same weight.
Quick takes:
- GPT-3.5 has the best pure conflict cross-play performance
- GPT-4 shows similar behavior on single-issue cooperation v. self-play

Table 4: Summary of average cross-play metrics. Higher is better except for Avg. Rounds. Here ‘soft/hard’ indicates the type of agreement. The former is reached when internal states align, the lather also requires a fixed agreement phrase being used by both agents.
Quick takes:
- Models seem to ‘copy’ each other’s behavior, with ‘bad’ self-play models strongly improving their metrics at the expense of the ‘good’ models. These results provide promising evidence that strong LMs could serve as effective ‘teachers’ for weaker models.
- For example, note Claude-2’s strong improvement in instruction-following for generative word restrictions.
Limitations (🤖🤚 : 💸💬⚙️…)
Two serious limitations of using dynamic, cross-model evaluations to measure language model agency are costs and prompt/settings sensitivity.
Costs: companies, governments, and researchers interested in benchmarking their models through cross-play will depend on third parties. This is currently not cheap… As the list of commercially viable LM providers increases this might prove prohibitively expensive. An alternative could be to test against ‘cheaper’ models and use latent-ability frameworks like the Elo rating system (as, e.g., used in chess) to extrapolate the ranking result.
Prompts and settings: We sought to ‘engineer’ prompts with minimal adverse effects across all models evaluated. However, a set of prompts likely exists that would be more beneficial for each model. We tried to alleviate this by running all models with a temperature of 0.2 and averaging results over many runs. Similarly, we took great care in selecting reasonable, unbiased default settings for our proposed architecture. Appendix A of our paper discusses various bias considerations and strategies to minimize their effects.
Conclusions and next steps (🧐🚀)
Autonomous agents powered by language models are rapidly entering our society. We argue that such dynamic applications require dynamic evaluations, jointly measuring performance and alignment metrics. Our proposed evaluation approach side-steps data leakage issues of static benchmarks and automatically co-evolves in difficulty with advances in language modeling power.
We open-source a flexible, no-code required code base and make the thousands of LM-agent negotiation transcripts generated during this project available for research. We hope that by open-sourcing our framework, we can convince more researchers from all disciplines to contribute to this fascinating new paradigm!
NEXT: Data, Code, Paper, and Contact (📂🤖🎓❓)
- 📂 data: all negotiation transcripts are openly available and can be used for research
- 🤖 code: check-out the source-code
- 🎓 paper: for more results and details on our evaluation framework, read our paper
- ❓ questions: please reach out!
Thanks for reading all the way to the end! If you have any questions or suggestions, please feel free to contact us :)
If you would like to use our code, data, or ideas in your own work - we would appreciate citing us as follows:
@misc{davidson2024evaluating,
title={Evaluating Language Model Agency through Negotiations},
author={Tim R. Davidson and
Veniamin Veselovsky and
Martin Josifoski and
Maxime Peyrard and
Antoine Bosselut and
Michal Kosinski and
Robert West},
year={2024},
eprint={2401.04536},
archivePrefix={arXiv},
primaryClass={cs.CL}
}